
Η META Παρουσιάζει το Llama 3 Beta στο Kοινό
Πώς το Llama 3 αλλάζει τα δεδομένα: Επισκόπηση των καινοτόμων μοντέλων τεχνητή νοημοσύνη της Meta με κορυφαίες επιδόσεις σε βιομηχανικά benchmarks.


Βασικά σημεία:
Σήμερα, σας παρουσιάζουμε το Meta Llama 3, την επόμενη γενιά του προηγμένου ανοικτού πηγαίου μοντέλου γλώσσας μας.
Τα μοντέλα Llama 3 θα είναι σύντομα διαθέσιμα σε AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM και Snowflake, με υποστήριξη από πλατφόρμες υλικού που προσφέρονται από AMD, AWS, Dell, Intel, NVIDIA και Qualcomm.
Είναι αφοσιωμένοι στο να αναπτύσσουν το Llama 3 με υπευθυνότητα και προσφέρουν διάφορους πόρους για να βοηθήσουν και άλλους να το χρησιμοποιήσουν με υπευθυνότητα. Αυτό περιλαμβάνει την εισαγωγή νέων εργαλείων εμπιστοσύνης και ασφάλειας με το Llama Guard 2, το Code Shield και το CyberSec Eval 2.
Τους επόμενους μήνες, αναμένουν να εισάγουν νέες δυνατότητες, μεγαλύτερα παράθυρα πλαισίου, επιπλέον μεγέθη μοντέλου και βελτιωμένες επιδόσεις, και θα μοιραστούν το έγγραφο έρευνας του Llama 3.
Σήμερα, είμαστε ενθουσιασμένοι να μοιραστούμε τα πρώτα δύο μοντέλα της επόμενης γενιάς του Llama, το Meta Llama 3, τα οποία είναι διαθέσιμα για ευρεία χρήση.
Αυτή η κυκλοφορία περιλαμβάνει προεκπαιδευμένα και λεπτομερώς προσαρμοσμένα μοντέλα γλωσσικής αναγνώρισης με 8 δισεκατομμύρια και 70 δισεκατομμύρια παραμέτρους που μπορούν να υποστηρίξουν μια ευρεία γκάμα περιπτώσεων χρήσης.
Αυτή η επόμενη γενιά του Llama δείχνει την τελευταία λέξη της τεχνολογίας σε μια ευρεία γκάμα βιομηχανικών δεικτών και προσφέρει νέες δυνατότητες, συμπεριλαμβανομένης της βελτιωμένης σκέψης.
Η META πιστεύει ότι αυτά είναι τα καλύτερα μοντέλα ανοιχτού κώδικα της κλάσης τους.
Είναι πράγματι μια αρκετά ισχυρή δήλωση από την Meta. Για να την υποστηρίξει, η εταιρεία επικαλείται τις επιδόσεις των μοντέλων Llama 3 σε δημοφιλείς βάσεις αξιολόγησης της Τεχνητής Νοημοσύνης όπως το MMLU, το ARC και το DROP.
Η χρησιμότητα και η εγκυρότητα αυτών των βάσεων αξιολόγησης είναι υπό αμφισβήτηση. Αλλά είτε το θέλουμε είτε όχι, παραμένουν ένας από τους λίγους τυποποιημένους τρόπους με τους οποίους παίκτες της ΤΝ όπως η Meta αξιολογούν τα μοντέλα τους.
META στόχοι για το Llama 3
Με το Llama 3, στόχευσαν να χτίσουν τα καλύτερα ανοιχτά μοντέλα που είναι συγκρίσιμα με τα καλύτερα προικισμένα μοντέλα που υπάρχουν σήμερα.
Ήθελαν να αντιμετωπίσουν τα σχόλια των προγραμματιστών για να αυξήσουν τη συνολική χρησιμότητα του Llama 3 και το κάνουν προχωρώντας στον ρόλο τους στην υπεύθυνη χρήση και ανάπτυξη των LLMs.
Προσφέρουν με ενθουσιασμό το Llama 3 στην κοινότητα ενώ βρίσκεται ακόμα σε ανάπτυξη, υιοθετώντας τη φιλοσοφία του ανοιχτού κώδικα που περιλαμβάνει τη διαρκή δημοσίευση νέων εκδόσεων για να επιτρέψει στην κοινότητα να αποκτήσει πρόσβαση σε αυτά τα μοντέλα.
Τα μοντέλα που βασίζονται σε κείμενο που κυκλοφορούν σήμερα είναι τα πρώτα στη συλλογή μοντέλων του Llama 3.
Ο στόχος τους στο άμεσο μέλλον είναι να καταστήσουν το Llama 3 πολύγλωσσο και πολυτροπικό, να έχει μεγαλύτερο περιεχόμενο και να συνεχίσει να βελτιώνει τη συνολική απόδοση σε βασικές ικανότητες των LLM όπως η σκέψη και ο προγραμματισμός.
Αποδόσεις Tελευταίας Tεχνολογίας
Τα νέα μοντέλα Llama 3 με παραμέτρους 8B και 70B αποτελούν ένα μεγάλο άλμα σε σχέση με το Llama 2 και καθιερώνουν ένα νέο state-of-the-art για τα LLM μοντέλα σε αυτές τις κλίμακες.
Χάρη σε βελτιώσεις στην προεκπαίδευση και τη μετα-εκπαίδευση, τα προεκπαιδευμένα και τα μοντέλα που έχουν διαμορφωθεί με οδηγίες είναι τα καλύτερα μοντέλα που υπάρχουν σήμερα στις κλίμακες 8B και 70B παραμέτρων.
Οι βελτιώσεις στις διαδικασίες μετα-εκπαίδευσης μείωσαν σημαντικά τα ποσοστά ψευδών αρνήσεων, βελτίωσαν την ευθυγράμμιση και αύξησαν την ποικιλία στις απαντήσεις του μοντέλου. Επίσης, παρατηρήθηκε σημαντική βελτίωση στις ικανότητες όπως η σκέψη, η δημιουργία κώδικα και η ακολούθηση οδηγιών, καθιστώντας το Llama 3 πιο ελεγξιμο.
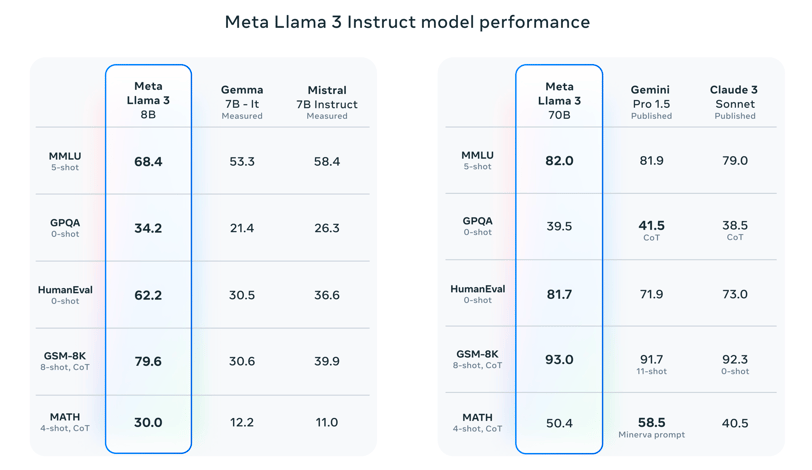
Το Llama 3 8B ξεπερνά σε επιδόσεις άλλα ανοικτά μοντέλα όπως το Mistral 7B της Mistral και το Gemma 7B της Google, τα οποία περιλαμβάνουν 7 δισεκατομμύρια παραμέτρους, σε τουλάχιστον εννέα benchmarks: MMLU, ARC, DROP, GPQA, HumanEval, GSM-8K, MATH, AGIEval και BIG-Bench Hard.
Το Llama 3 70B νικάει το Gemini 1.5 Pro σε MMLU, HumanEval και GSM-8K, και - ενώ δεν ανταγωνίζεται το πιο αποδοτικό μοντέλο της Anthropic, το Claude 3 Opus - το Llama 3 70B σκοράρει καλύτερα από το δεύτερο αδύναμοτερο μοντέλο στη σειρά Claude 3, το Claude 3 Sonnet, σε πέντε benchmarks (MMLU, GPQA, HumanEval, GSM-8K και MATH).
Προσωπικό τεστ επιδόσεων LLAMA 3 του META
Κατά την ανάπτυξη του Llama 3, η ομάδα εξέτασε την απόδοση του μοντέλου σε τυπικά benchmarks και επιδίωξε επίσης τη βελτιστοποίηση για πραγματικά σενάρια. Για τον σκοπό αυτό, ανέπτυξαν ένα νέο υψηλής ποιότητας σύνολο ανθρώπινης αξιολόγησης.
Αυτό το σύνολο αξιολόγησης περιλαμβάνει 1.800 αιτήματα που καλύπτουν 12 βασικές περιπτώσεις χρήσης: ζήτηση συμβουλής, σύλληψη ιδεών, ταξινόμηση, απάντηση σε κλειστές ερωτήσεις, προγραμματισμός, δημιουργική γραφή, εξαγωγή, ενσάρκωση χαρακτήρα/προσωπικότητας, απάντηση σε ανοιχτές ερωτήσεις, συλλογισμός, επανασύνταξη και περίληψη.
Για να αποτρέψουν την ακούσια υπερπροσαρμογή των μοντέλων τους σε αυτό το σύνολο αξιολόγησης, ακόμη και οι δικές τους ομάδες μοντελοποίησης δεν είχαν πρόσβαση σε αυτό.
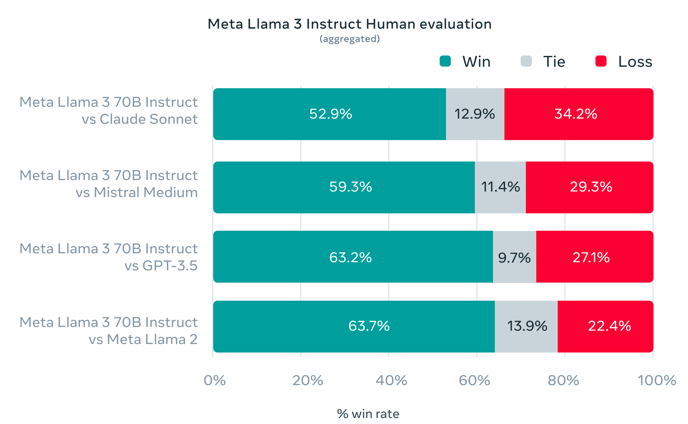
Ο παρακάτω πίνακας δείχνει τα συγκεντρωμένα αποτελέσματα των ανθρώπινων αξιολογήσεων σε αυτές τις κατηγορίες και τα αιτήματα έναντι των Claude Sonnet, Mistral Medium και GPT-3.5.
Αρχιτεκτονική Mοντέλου
Σύμφωνα με τη φιλοσοφία σχεδιασμού τους, επέλεξαν μια σχετικά τυπική αρχιτεκτονική μετατροπέα μόνον αποκωδικοποίησης στο Llama 3.
Σε σύγκριση με το Llama 2, έκαναν αρκετές κλειδιά βελτιώσεις. Το Llama 3 χρησιμοποιεί έναν tokenizer με ένα λεξιλόγιο των 128 χιλιάδων διακριτικών στοιχείων που κωδικοποιεί τη γλώσσα πολύ αποτελεσματικότερα, οδηγώντας σε σημαντική βελτίωση της απόδοσης του μοντέλου.
Για τη βελτίωση της αποδοτικότητας επιστροφής των μοντέλων Llama 3, υιοθέτησαν την ομαδοποιημένη προσοχή ερωτήματος (GQA) και στα δύο μεγέθη, 8B και 70B. Eκπαιδεύοντας τα μοντέλα σε ακολουθίες των 8.192 διακριτικών στοιχείων, χρησιμοποιώντας ένα μάσκα για να διασφαλίσουν ότι η αυτοπροσοχή δεν διασχίζει τα όρια του εγγράφου.
Δεδομένα Eκπαίδευσης
Για την εκπαίδευση του καλύτερου μοντέλου γλώσσας, η δημιουργία ενός μεγάλου, υψηλής ποιότητας συνόλου δεδομένων εκπαίδευσης είναι ζωτικής σημασίας.
Σύμφωνα με τις αρχές σχεδιασμού τους, επενδύθηκαν σημαντικά στα δεδομένα προεκπαίδευσης. Το Llama 3 εκπαιδεύεται σε πάνω από 15 τρισεκατομμύρια διακριτικά στοιχεία που συλλέχθηκαν όλα από δημόσιες πηγές. Το σύνολο δεδομένων εκπαίδευσής του είναι επτά φορές μεγαλύτερο από αυτό που χρησιμοποιήθηκε για το Llama 2, και περιλαμβάνει τέσσερις φορές περισσότερο κώδικα.
Για να προετοιμαστούν για τις επερχόμενες πολύγλωσσες περιπτώσεις χρήσης, πάνω από το 5% του συνόλου δεδομένων προεκπαίδευσης του Llama 3 αποτελείται από υψηλής ποιότητας μη-αγγλικά δεδομένα που καλύπτουν πάνω από 30 γλώσσες. Ωστόσο, δεν αναμένουν το ίδιο επίπεδο απόδοσης σε αυτές τις γλώσσες όπως στα αγγλικά.
Για να διασφαλίσουν ότι το Llama 3 εκπαιδεύεται με δεδομένα υψηλής ποιότητας, ανέπτυξαν μια σειρά από αγωγούς φιλτραρίσματος δεδομένων. Αυτοί οι αγωγοί περιλαμβάνουν τη χρήση ευρηματικών φίλτρων, φίλτρων NSFW, προσεγγιστικών προσεγγίσεων αφαίρεσης διπλοεγγραφών και ταξινομητών κειμένου για να προβλέψουν την ποιότητα των δεδομένων.
Βρήκαν ότι οι προηγούμενες γενιές του Llama είναι εκπληκτικά καλές στο να αναγνωρίζουν δεδομένα υψηλής ποιότητας, γι' αυτό και χρησιμοποίησαν το Llama 2 για να δημιουργήσουν τα δεδομένα εκπαίδευσης για τους ταξινομητές ποιότητας κειμένου που τροφοδοτούν το Llama 3.
Τι είναι το επόμενο βήμα για το Llama 3?
Τα μοντέλα Llama 3 8B και 70B αποτελούν την αρχή του σχεδιασμού τους για το τι προτίθενται να κυκλοφορήσουν για το Llama 3. Και υπάρχει πολύ περισσότερο στον ορίζοντα.
Τα μεγαλύτερα μοντέλα τους έχουν πάνω από 400 δισεκατομμύρια παραμέτρους και, ενώ αυτά τα μοντέλα εξακολουθούν να εκπαιδεύονται, η ομάδα τους είναι ενθουσιασμένη με την εξέλιξή τους.
Της επόμενες μήνες, θα κυκλοφορήσουν πολλαπλά μοντέλα με νέες δυνατότητες, συμπεριλαμβανομένης της πολυτιμότητας, της δυνατότητας να μιλούν σε πολλές γλώσσες, ένα πολύ μεγαλύτερο παράθυρο πληροφοριών και γενικότερες ισχυρότερες δυνατότητες. Θα δημοσιεύσουν επίσης ένα λεπτομερές ερευνητικό άρθρο μόλις τελειώσουν την εκπαίδευση του Llama 3.
Για να σας δώσουν μια πρώτη γεύση για το πού βρίσκονται αυτήν τη στιγμή αυτά τα μοντέλα καθώς συνεχίζουν την εκπαίδευσή τους, σκέφτηκαν να μοιραστούν μερικά στιγμιότυπα του πώς εξελίσσεται το μεγαλύτερο μοντέλο LLM. Σημειώστε ότι αυτά τα δεδομένα βασίζονται σε ένα νωρίς σημείο ελέγχου του Llama 3 που εξακολουθεί να εκπαιδεύεται και αυτές οι δυνατότητες δεν υποστηρίζονται ως μέρος των μοντέλων που κυκλοφόρησαν σήμερα.


Πηγές:
Meta AI. (n.d.). Meta Llama 3. Meta AI. Retrieved from https://ai.meta.com/blog/meta-llama-3/
TechCrunch. (2024, April 18). Meta releases Llama 3, claims it's among the best open models available. TechCrunch. Retrieved from https://techcrunch.com/2024/04/18/meta-releases-llama-3-claims-its-among-the-best-open-models-available/